Начиная с версии hardware version 9, виртуальные машины поддерживают новый формат виртуальных дисков Space Efficient Sparse. Один из механизмов, для работы которого требуются SE Sparse диски - Space Reclamation в VMware Horizon View, позволяющий высвобождать неиспользуемое дисковое пространство из vmdk файлов, что особенно важно в случае использования постоянных linked-clone машин, которые имеют тенденцию разрастаться по мере работы.
Для включения и работы Space Reclamation должны быть выполнены следующие условия:
ВМ должны быть созданы в режиме linked-clone. Full-clone виртуальные машины не поддерживаются.
ВМ и мастер-образ, из которого она создана, должны иметь hardware version 9 или выше. На хостах должна быть установлена VMware ESXi 5.1 или выше.
Поддерживаются только диски, подключенные к SCSI контроллерам. IDE диски не поддерживаются.
Поддерживаются только ОС Windows XP и Windows 7. Windows 8 не поддерживается.
К сожалению, часто администраторы View, особенно те, что управляют виртуальной инфраструктурой через толстый клиент vSphere Client, не обращают внимания на версию ВМ и создают мастер-образ на базе hardware version 8. И как результат - опция Space Reclamation становится недоступной в свойствах пула.
Что делать, если пул и виртуальные машины уже созданы, а включить space reclamation надо?
Порядок включения Space Reclamation таков: 1. Если вы используете автоматическое создание виртуальных рабочих станций в пуле, временно отключите его (Disable Provisioning).
2. Выполните обновление ВМ в пуле до новой hardware version (9 или 10). Для удобства вы можете запланировать автоматическое обновление при следующем выключении ВМ из консоли vSphere Web Client.
3. Проверьте версии VMware Tools и VMware View Agent, установленные в гостевой ОС мастер-образа, и, при необходимости, обновите их. 4. Обновите hardware version ВМ мастер-образа. 5. Создайте мгновенный снимок мастер-образа и в свойствах пула замените устаревший образ на новый.
6. Включите, если был отключено создание ВМ в пуле (Enable Provisioning). 7. Выполните процедуру recompose для всех ВМ в пуле, чтобы они могли использовать новые Sparse диски.
8. Включите Space Reclamation (Reclaim VM disk space) в свойствах пула.
Проверить, что функция Space Reclamation корректно работает можно, запустив процедуру вручную на одной из обновленных ВМ:
Уже не раз я сталкиваюсь с ситуацией, когда по тем или иным причинам требуется сменить сеть на ВМ, созданных с помощью linked-clone. В основном это требуется, когда старая группа портов подключена к сети, где не хватает свободных IP-адресов или используется группа портов на стандартном виртуальном коммутаторе и требуется мигрировать ВМ на распределенный коммутатор и т.д.
Для решения этой задачи есть один правильный способ, который включает в себя следующие шаги:
Подключить виртуальные сетевые адаптеры существующих ВМ к новой группе портов.
Подключить виртуальный сетевой адаптер на ВМ, которая используется в качестве мастер-образа, к новой группе портов.
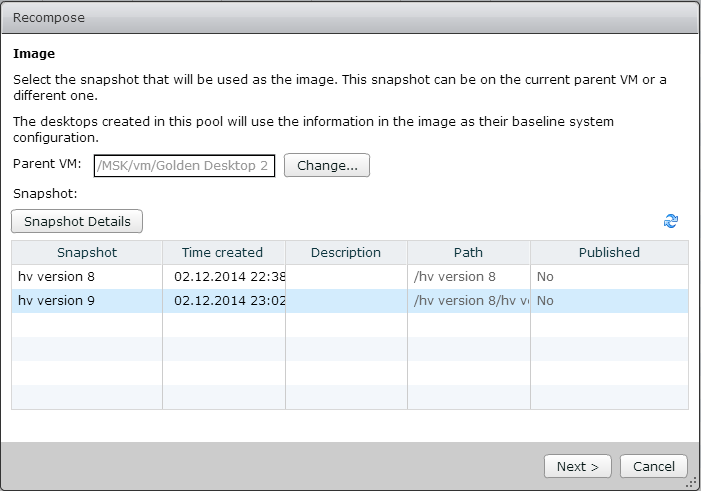
Создать новый снапшот с мастер-образа и запустить Recompose для всех ВМ, которые были созданы из старого мастер-образа.
Recompose требуется, чтобы удалить все реплики ВМ (replica-*), которые подключены к старой группе портов.
Однако, Recompose удалит все данные с дельта дисков ВМ, что может не подойти в случае использования постоянных выделенных ВМ (persistent, dedicated).
Поэтому есть второй (и по всей видимости, неподдерживаемый) способ, который не требует запуска Recompose, но, в теории, может кое-что поломать в вашей инфраструктуре, поэтому используйте его на свой страх и риск:
Подключить виртуальные сетевые адаптеры существующих ВМ к новой группе портов.
Отключить защиту от изменений для реплики мастер-образа, из которой создаются ВМ.
Подключить виртуальные сетевые адаптеры реплики мастер-образа к новой группе портов. Это избавит от необходимости делать Recompose на всех машинах.
Отредактировать конфигурационный файл снапшота реплики мастер-образа (.vmsn) и прописать в нем подключение к новой группе портов. Это нужно, чтобы все новые ВМ, создаваемые из реплики, подключались к нужной сети. Настройки ID группы портовВ качестве альтернативного варианта можно настроить Multiple Network Labels, доступные в View 5.2 и новее.
Загрузить настройки из отредактированного .vmsn файла в память гипервизора.
Включить защиту от изменений для реплики мастер-образа. Чтобы её никто случайно не сломал.
Для упрощения процедуры переключения большого кол-ва ВМ из одной группы портов в другую можно использовать мастер миграции.
По умолчанию, все реплики мастер-образов защищены от изменения и удаления и изменение настрое (Edit Settings) недоступно из интерфейса vSphere.
Для отключения защиты требуется использовать утилиту sviconfig.exe, расположенную на сервере View Composer в каталоге "C:\Program Files (x86)\VMware\VMware View Composer\". Команда имеет следующие параметры: sviconfig.exe -operation=unprotectentity -DsnName=<ODBC_коннектор> -dbusername=<пользователь_СУБД> -dbpassword=<пароль_пользователя_СУБД> -vcurl=<Путь_к_vCenter> -vcusername=<пользователь_vCenter> -inventorypath=<Путь_к_реплике>
, где: <ODBC_коннектор> - имя ODBC коннектора, который используется для подключения к базе данных Composer. Можно посмотреть через консоль ODBC Data Source Administrator на вкладке System DNS;
<пользователь_СУБД> - имя учетной записи пользователя, который используется для подключения к БД Composer;
<пароль_пользователя_СУБД> - пароль учетной записи пользователя, который используется для подключения к БД Composer;
<Путь_к_vCenter> - путь к каталогу /sdk сервера vCenter Server (например, "https://vcenter.domain.local/sdk")
<пользователь_vCenter> - имя учетной записи пользователя для подключения к серверу vCenter Server.
<Путь_к_реплике> - полный путь к ВМ реплики, начиная с корневого каталога виртуального ЦОД сервера vCenter (по умолчанию, все реплики создаются в подкаталоге "/<Имя_ВЦОД>/vm/VMwareViewComposerReplicaFolder/", который можно видеть в дереве каталога vCenter).
После снятия защиты можно изменить настройки реплики мастер-образа и подключить ее к другой группе портов.
Отредактировать vmsn файл можно с помощью редактора vi из консоли ESXi.
Параметры, которые требуется изменить:
ethernet[x].dvs.switchId;
ethernet[x].dvs.portId;
ethernet[x].dvs.portgroupId;
ethernet[x].dvs.connectionId.
Самый простой способ - скопировать настройки из .vmx файла реплики, расположенного в той же папке.
Так как .vmsn файл редактируется вручную, требуется обновить настройки в памяти гипервизора. Сделать это можно, удалив ВМ из инвентаря (remove from inventory) и добавив ее заново (Add to inventory) в тот же пул ресурсов и в тот же каталог, или перенеся ВМ с одного ESXi сервера на другой с помощью Migrate.
Последний шаг - включение защиты от изменений для реплики (чтобы ничего ненароком не сломать), выполняется той же утилитой sviconfig.exe с параметром -operation=protectentity: sviconfig.exe -operation=unprotectentity -DsnName=<ODBC_коннектор> -dbusername=<пользователь_СУБД> -dbpassword=<пароль_пользователя_СУБД> -vcurl=<Путь_к_vCenter> -vcusername=<пользователь_vCenter> -inventorypath=<Путь_к_реплике>
Последний день на конференции порадовал хорошими докладами.
Для начала, я посетил STO1153 - Performance Best Practices to Run Virtualized Applications on Virtual SAN, где рассказывалось, как правильно тестировать производительность VSAN, а также, что нужно делать для оптимизации производительности.
В начале года были опубликованы результаты тестов производительности VSAN на сайте VMware. Так, например, в тесте VSAN кластера из 32 узлов в режиме 100% чтения блоками по 4 КБ удалось достичь впечатляющих показателей в 2 миллиона IOPS. Не менее интересными выглядят графики для смешанного типа нагрузки и нагрузок для большого тестового объема данных.
Из графиков видно, что увеличение количества узлов в кластере обеспечивает, практически, линейную производительность.
Не менее интересно выглядят результаты производительности для различных приложений:
Готовится к выходу Virtual Infrastructure Planner, предназначенный для сайзинга Virtual SAN. Данная утилита собирает статистику загрузки текущей инфраструктуры и выдает отчет об уровне ввода-вывода, рекомендации по построению кластера VSAN и расчет экономии капитальных затрат при переходе на VSAN.
Также были даны рекомендации по измерению производительности VSAN. Для правильных замеров производительности следует:
Дать время на "прогрев" SSD кэша.
Мониторить метрики производительности на каждом хост-сервере.
Обратить внимание на следующие ситуации: частоту обращения к SSD кэшу, когда размер тестовой области не укладывается в кэш, снижение производительности при операциях записи, рост времени задержек при обращении к жестким дискам, чрезмерная загрузка CPU.
Для оценки производительности рекомендуется использовать утилиты типа VSAN Observer или ESXTop.
Для достижения оптимального уровня производительности следует придерживаться следующих рекомендаций:
Обеспечить необходимое соотношение SSD/HDD для того, чтобы активные данные попадали в кэш.
Учитывать размер страйпа (кол-во HDD, по которым распределяются vmdk диски).
Увеличивать объем дискового пространства, отводимого под read cache для ВМ, если производительность ввода/вывода недостаточна.
Для SSD - обращать внимание не только на производительность операций чтения, но и на производительность записи.
Для HDD - использовать более быстрые диски (10k или 15k RPM) для увеличения производительности записи.
Доклад SDDC1337 - EVO:RAIL Technical Deep Driver был посвящен внутреннему устройству EVO:RAIL. EVOL:RAIL строится на базе зарекомендовавшего себя набора продуктов: ESXi, vCenter Server, VSAN, Log Insight, снабженного ПО EVO:RAIL Engine для быстрого и простого развертывания. Консоль EVO:RAIL позволяет за 15 минут развернуть полностью готовый к работе виртуальную инфраструктуру из 4-х серверов, и, при необходимости, расширить ее до 16 серверов. Все управление осуществляется из web-интерфейса, написанного на HTML5 (никакого Flash). Серверная часть EVO:RAIL Engine интегрирована прямиком в vCenter Server Appliance, а клиентская часть (LoudMouth Daemon) - прямиком в гипервизор ESXi, а это значит - никаких лишних виртуальных машин для управления. Особую роль в архитектуры EVO:RAIL играют две технологии: Multicast DNS (mDNS) и DNS Service Discovery (DNS-SD), обеспечивающие автоматическое обнаружение и настройку новых хост-серверов.
Кстати, изначально проект носил название MARVIN (Modular Automated Rackable Virtual Infrastructure Node) - отсылка к одноименному персонажу книги "Автостопом по Галактике".
И зачем только VMware заменили этого милого робота на кибер-таракана?
В последний день участники выставки уже порядком подустали и уже не так охотно отвечали на вопросы: "Что вы делаете?" и "Чем вы круче вон тех ребят?". Из запомнившегося стоит отметить компанию Stromasys - разработчика эмуляторов VAX, Alpha и HP3000 для платформ Intel x86 и гипервизора VMware ESXi. На сегодняшний день во многих компаниях, связанных с производством, есть критичные приложения, которые по тем или иным причинам не могут или не хотят портировать. Используя ПО эмуляции можно обеспечить должный уровень производительности и доступности для этих приложений на современном оборудовании.
vGirls
Завершить рассказать о конференции я бы хотел небольшой подборкой фотографий с выставки.
Продолжение рассказа о конференции VMworld Europe 2014. Предыдущие части доступны тут и тут.
Второй день также начался с генеральной сессии, на которой больше внимание уделялось демонстрации технических возможностей новых продуктов. В частности, как легко и просто создать новое облако с поддержкой управления Open Stack прямо из консоли vSphere Web Client, а затем мониторить его с помощью vRealize Operations.
Кстати, не так давно вышла отличная книга Open Stack Architecture Design Guide написанная в соавторстве группой ведущих специалистов по облачным технологиям, работающих в таких компаниях, как: Cisco, Clouscaling, Comcast, EMC, Mirantis, Rackspace, Red Hat, Verizon и VMware.
Не забыли упомянуть про открытую бета версию vSphere 6.0, представившей множество нововведений: многопроцессорный Fault Tolerance, миграцию vMotion между различными серверами vCenter, поддержку VVols, vSAN 2.0.
Под конец выступления было продемонстрировано, как легко и просто можно переносить сервисы из внутренней инфраструктуры в публичное облако VMware vCloud Air и обратно. Так, например, при использовании vCloud Connector все правила на виртуальном брандмауэре переносятся мигрируют вместе с ВМ.
На сессии SDDC3281 A DevOps Story: Unlocking the Power of Docker with the VMware Platform and Its Ecosystem рассказывали о том, с какими проблемами сталкиваются современные разработчики ПО. Серверная виртуализация предлагает различные преимущества: абстрагирование от конкретного серверного оборудования, возможность миграции нагрузок между физическими серверами, развитые средства управления ВМ и виртуальными сетями (NAT, Network Virtualization, IPAM). И все было бы хорошо, но основная претензия разработчиков заключается в том, что серверная виртуализация не позволяет достаточно быстро развертывать тестовые среды. Процедуры клонирования и подготовки могут отнимать много времени, и в результате, вместо того, чтобы заниматься написанием кода, разработчики занимаются поддержкой своей инфраструктуры. Для решения этих проблем применяется контейнерная виртуализация (на базе Docker), с помощью которой возможно быстро-быстро разворачивать новые сервисы, изолированные друг от друга. VMware планирует объединить серверную и контейнерную виртуализацию для задач разработки и тестирования, и взять лучшее от каждого из решений. Для этого предлагается отказаться от классической схемы "холодного" клонирования ВМ из шаблонов и вместо этого клонировать машины на лету. В каждой такой машине, в свою очередь, предполагается создавать контейнеры Docker, обеспечивающие изоляцию приложений от ОС и друг от друга.
Данная инициатива получила название Project Fargo и уже нашла применение в смежной области - VDI, где аналогичным образом планируется создавать клоны клиентских виртуальных рабочих станций, совместно с технологиями распространения приложений (ThinApp, Cloud Volumes).
Для автоматизации управления процедурой развертывания планируется использовать зарекомендовавший себя продукт vRealize Automation, а также наработки партнеров (Cloud Foundry от Pivotal).
Следующая сессия STO2997-SPO - The vExpert Storage Game Show EMEA проходила в не совсем обычном формате - в виде аналога телешоу Jeopardy ("Своя Игра"). В ней две команды - сотрудников VMware и сотрудников Pure Storage (производителя All flash систем хранения) соревновались в знании технологий хранения данных.
Вопросы, надо сказать, были не из легких. Я, например, был совершенно не в курсе - какая стандартная и максимальная глубина очереди на PVSCSI контроллерах в виртуальных машинах или какие изменения произошли в функционале UNMAP между vSphere 5.1 и vSphere 5.5.
На сессию SDDC1176 Ask the Experts vBloggers стоило прийти хотя бы ради именитых выступающих: Scott Lowe, Chad Sakac, Duncan Epping, Eric Sloof - культовые личности мира виртуализации. Выступающие поделились секретом, как им удается совмещать работу, личную жизнь и ведение блогов, развеяли слухи о возможном приобретении компанией HP бизнеса EMC или VMware, рассказали о том, что важно участвовать в жизни ИТ-коммьюнити и делиться своими наработками с коллегами по цеху.
На выставке я посетил стенд Nutanix (лидер рынка гиперконвергентных решений), на котором демонстрировались возможности новой версии NOS 4.1. Главное нововведение - поддержка географически распределенного кластера (Metro Availability). Данная возможность отлично подойдет для организации катастрофоустойчивых решений на базе VMware vSphere, требующих низких значений RPO и RTO. Metro Availability доступен в редакции Ultimate и не требует покупки дополнительного оборудования или лицензий, а также крайне прост в настройке. Другим интересным продуктом, готовящимся к выходу, является Nutanix Acropolis, позволяющий создавать свое облако на базе бесплатного гипервизора KVM. Добавьте к этому крайне удобный. функциональный и быстрый web-интерфейс, которым отличаются продукты Nutanix, и получите решение, способное потеснить Mirantis OpenStack, а то и VMware vCloud Suite.
На стенде Commvault показывали новый смертельный номер.
Вот такие фокусы показывали на стенде Arista Networks.
Завершила день традиционная вечеринка, на которой подавали прекрасную грибную паэлью и хамон.
Продолжение рассказа о конференции VMworld Europe 2014. С первой частью можно ознакомиться тут.
День начался с традиционной пленарной сессии.
Как и в прошлом году основными направлениями развития VMware остаются:
программно-определяемые ЦОД (SDDC - Software Defined Datacenter);
облачные вычисления; (Cloud Computing);
приложения и сервисы для конечных пользователей (End-user computing);
Для реализации концепции SDDC компания VMware предлагает VMware NSX, VMware VSAN, а также совместно с партнерами разрабатывает гиперконвергентную инфраструктуру VMware EVO:RAIL. Вдобавок к Dell, EMC, Fujitsu, Inspur, Net One и Supemicro, производящих оборудование и осуществляющих поддержку EVO:RAIL, на конференции было объявлено о присоединении к программе еще двух крупных игроков: HP и Hitachi. Кроме того, был анонсирован tech preview платформы EVO:RACK, которая предназначена для заказчиков, покупающих оборудование целыми стойками. В основе EVO:RACK лежит Open Compute Project, меняющий представление о классической организации серверного оборудование и стоек, и призванного решить многие проблемы, связанные с плотностью размещения, электропитанием и охлаждением серверного оборудования. Другими важными компонентами EVO:RACK являются VMware vRealize Operations и VMware NSX, решающие задачи мониторинга инфраструктуры и виртуализации сетей соответственно.
Одной из проблем, с которой сталкиваются современные компании, занимающиеся разработкой продуктов, является использование различного набора ПО для организации производственной инфраструктуры и инфраструктуры для тестирования и разработки. Разработчики могут использовать ОС на базе *nix и контейнерную виртуализацию, а также Openstack для управления всем этим хозяйством, в то время, как в производственной инфраструктуре используется ПО VMware. Это приводит к тому, что, разработчики, вместо того, чтобы заниматься разработкой, по-сути, самостоятельно поддерживают весь зоопарк ПО, т.к. ИТ-поддержка отказывается работать с "не-enterprise решениями".
Решение этой проблемы - использовать OpenStack, построенный на базе продуктов и решений VMware (vSphere, NSX, VSAN), что позволит получить единую надежную, управляемую, масштабируемую платформу для решения любых задач.
На сессии было сказано несколько слов и про контейнерную виртуализацию. На сегодняшний день контейнерная виртуализации (на базе Docker) является весьма горячей темой для обсуждения. Именно поэтому VMware совместно с партнерами (Pivotal) разрабатывает решения (Project Fargo, Cloud Foundry), позволяющие интегрировать контейнерную виртуализацию в экосистему продуктов VMware.
VMware NSX стремительно развивается. По всему миру насчитывается уже более 250 заказчиков, внедривших в своей инфраструктуре NSX. Более 40 партнеров разрабатывают различные решения, завязанные на NSX.
Аналитическое агенство Gartner включило VMware в свой магический квадрат Data Center Networking.в качестве компании, задающей направление развития сетевой инфраструктуры в ЦОД.
В области End-user Computing за год произошли значительные изменения: закрытие сделки по приобретению Desktone - крупнейшего сервис-провайдера Desktop as a Service, закрытие сделки по приобретению AirWatch - лидера рынка управления мобильными устройствами (MDM - mobile device management), партнерство с NVIDIA и Google по развитию технологий ускорения 3D графики в VDI, релиз VMware Horizon 6, покупка компании CloudVolumes - разработчика решения доставки приложений на виртуальные машины.
Публичное облако VMware vCloud Air (бывший vCloud Hybrid Services) шагает по планете. VMware заявляет о поддержке облака чуть ли не в каждом своем продукте. Так, например, новая версия vSphere Replication прямо из коробки поддерживает возможность репликации ВМ прямо в облако VMware Air. Интерфейс vSphere Web Client поддерживает управление облаком, vRealize Operations 6.0 имеет соответствующий Management Pack для мониторинга, vRealize Automation, так вообще, является единой платформой для управления как частными, так и публичными облаками. Тем не менее, VMware всеми силами открещивается от именования vCloud Air публичным облаком, старательно называя его гибридной облачной платформой.
На конференции были анонсированы новые услуги на базе vCloud Air: СУБД как сервис (Database as-a Service), объектное хранилище (на базе EMC ViPR), но самое главное - это запуск тестовой версии облака Virtual Private Cloud OnDemand с моделью оплаты за использованные ресурсы (pay as you go), т.е. плата будет взиматься за фактический объем потребленных ресурсов (мегагерц процессора, мегабайт памяти и дискового пространства, операций ввода-вывода и т.д.). Такую же модель оплаты предоставляют другие облачные провайдеры типа Amazon или Microsoft.
На презентации также было показано, как с помощью Cloud Volumes становится возможным установить на виртуальную машину более сотни приложений всего за несколько секунд.
Первая сессия INF1311 Deploy and Destroy 85K VMs in a Week: VMware Hands-on Labs Backstage раскрыла секреты инфраструктуры, на которой проводятся лабораторные работы Hands-on Labs. Секрета, в общем-то, никакого и нет, все делается на стандартном наборе ПО, разрабатываемом VMware: vSphere, vShield Manager, vCloud Director, vCOps, Log Insight.
Важным условием при подготовке лабораторной работы является то, что все компоненты должны быть виртуальными - никакого специализированного оборудования, даже в партнерских лабораторных работах. В основном используются серверы Cisco UCS и СХД EMC VNX и XtremIO, хотя в последнее время происходит активный переход на EVO:RAIL. В качестве протокола подключения к хранилищам в основном используется iSCSI, также присутствует NFS, но он используется только для задач распространения новых лабораторных работ.
Основная нагрузка на лабораторию приходится на дни проведения конференций VMworld и Partner Exchange.
Интересным архитектурным решением является наличие большого числа серверов управления vCenter Server (по одному на кластер vSphere) и vCloud Director. Сделано это из-за архитектурных ограничений - количества одновременных операций развертывания ВМ из шаблонов, создания linked-клонов, миграции ВМ, накладываемых одним vCenter.
Основная проблема, с которой сталкиваются администраторы лаборатории - это патч-менеджмент и распространение новых лабораторных работ во все ЦОД. Из-за работы лаборатории в режиме 24x7 и требования единообразия инфраструктуры, решение об установке обновлений может затягиваться, хотя часто в лаборатории используются бета версии еще не вышедших продуктов или билды, недоступные конечным заказчикам, что также может вносить дополнительные сложности. Лабораторные работы копируются, преимущественно, вручную, путем экспорта и импорта шаблонов vApp в каталоги vCloud Director.
Вторая сессия - STO25520SPO, How VMware Virtual Volumes (VVols) Will Provide Shared Storage with X-ray Vision, носила преимущественно маркетинговый характер, к тому же, читалась по слайдам прошлого года, поэтому особой пользы от нее не было.
Вкратце, VVols несмотря на кажущуюся сложность, весьма прост в настройке и позволяет решать множество проблем, возникающих из-за использования томов СХД для хранения ВМ. VVols позволяет администраторам получить лучшее от двух миров SAN и NAS систем, и фактически, является той самой долгожданной, прорывной, технологией, которая даст толчок всей индустрии СХД.
Кстати, для меня было новостью, что HP 3PAR является референсной платформой для разработки VVols для Fibre Channel СХД.
Дальше была выставка партнерских достижений.
На стенде Oracle красовалась надпись: "Виртуализуй в 7-10 раз быстрее с Oracle VM". -Хорошая штука! - подумал я и не стал подходить.
Партнерам, которым не досталось слотов для проведения сессий, читали мини-лекции прямо на стендах. Для привлечения потенциальных слушателей использовались всевозможные "грязные" приемы, вроде маек в подарок или участия в лотерее с возможностью выиграть iPhone, iPad, bluetooth аудиосистему, квадрокоптер.
На общем фоне отличилась компания Simplivity, разыграв... BMW i8.
Хорошие у ребят маркетинговые фонды.
Интересная задумка с подарками была на стенде Fujitsu - всем прослушавшим лекцию давали купон на мышку, на которой тут же на стенде можно было нанести любую понравившуюся надпись с помощью лазера. К сожалению, данная операция занимала довольно продолжительное время, а желающих было много, поэтому жадным до халявы посетителям приходилось ждать по 40 минут в огромной очереди. Вот, кстати, моя мышка.
Посетителей развлекали как могли. Кто-то участвовал в гонках.
Кого-то умелые фокусники разводили на часы, обручальные кольца и 10 евро.
Из интересного стоит отметить отдельный демонстрационный зал EVO Zone, где партнеры VMware показывали оборудование EVO:RAIL.
Поскольку спецификация оборудования предоставляется самой VMware, то конфигурация у всех производителей максимально однотипна:
шасси высотой 2U, в которое устанавливается 4-е сервера;
2 шестиядерных процессора Intel Xeon E5-2620 (v2 или v3);
192 ГБ оперативной памяти;
14,4 ТБ сырой емкости на жестких дисках;
1,6 ТБ сырой емкости на SSD накопителях для кэширования;
2 порта Ethernet 10G (с разъемами RJ-45 или SFP+).
EVO:RAIL от Dell.
EVO:RAIL от HP на базе платформы HP Proliant SL2500.
EVO:RAIL от Fujitsu, а возможно от Inspur, хотя я уже запутался.
В общем, суть вы уловили.
На входе в демо-зону стоял один единственный EVO:RACK. Отличить его оказалось очень просто из-за нестандартной стойки и специфичного вида оборудования (Open Compute Project).
На стенде HP демонстрировали много всего интересного, в том числе прошедшие мимо меня серверы Proliant 9-го поколения. Главной отличительной особенностью 9-го поколения стала поддержка процессоров Intel Haswell, и, как следствие, больших объемов памяти (до 768 ГБ на моделях HP Proliant DL360 или DL380). Из приятных мелочей - в базе у сервера 4 Ethernet порта 1 Гбит/с, а в разъем Flexible LOM, впервые появившийся в GEN8, можно опционально установить 1/10 Гбит/с Ethernet или Infiniband адаптеры. Кстати, материнская плата у HP Proliant DL360 и DL380 теперь одинаковая, а модель системы определяется угадайте чем? Блоком вентиляторов системы охлаждения!
Для блейд-серверов HP Proliant BL460c Gen9 появилась возможность использования двухпортовых 20 Гбит/с конвергентных адаптеров (но только в сочетании с определенными коммутационными модулями блейд-шасси). Это позволяет отказаться от покупки дополнительных мезанинных карт (Fibre Channel или Ethernet), поскольку пропускной способности встроенного адаптера должно хватить для работы и 10 Гбит/с виртуального nic адаптера, и для 8 Гбит/с виртуального hba адаптера.
На стенде Teradici (разработчик протокола PCoIP) демонстрировались возможности новой прошивки для нулевых клиентов, обеспечивающей оптимизацию передачи потокового аудио (например при голосовых звонках с одной виртуальной рабочей станции на другую).
Также я записал небольшое видео, наглядно демонстрирующее преимущество использования аппаратных графических адаптеров и ускорителей PCoIP.
На стенде Bull демонстрировали новое поколение сервера Bullion (S2, S4, S8, S16). Сервер имеет модульную архитектуру, включающую в себя от одного до восьми вычислительных узлов. Каждый узел представляет собой 3U двухпроцессорный сервер, который коммутируется с другими узлами через внешний коммутатор (Bull Coherency Switch). Объединенные таким образом узлы могут работать как единый 16 сокетный сервер (суммарно до 240 ядер) с 24 ТБ оперативной памяти (не хило!). Сервер имеет модульную архитектуру, оперативная память и адаптеры ввода-вывода устанавливается в специальные картриджи.
На этой позитивной ноте я завершу сегодняшний рассказ. Продолжение следует.