Небольшая заметка о том, каким образом VMware vCenter Server хранит разрешения на управление виртуальной инфраструктурой.
Все разрешения хранятся в виде записей в таблице dbo.VPX_ACCESS в базе Microsoft SQL Server'а.
Все разрешения хранятся в виде записей в таблице dbo.VPX_ACCESS в базе Microsoft SQL Server'а.

Всего в таблице пять столбцов:
ID - уникальный идентификатор.
PRINCIPAL - имя учетной записи пользователя или группы для которых назначаются права. Задаются в формате <ИМЯ_ЗАПИСИ> или <ДОМЕН\ИМЯ_ЗАПИСИ>.
ROLE_ID - идентификатор роли, содержащий необходимые права.
ENTITY_ID - идентификатор объекта, на который назначаются разрешения.
FLAG - переключатель хранит информацию о наследовании и типе учетной записи (пользователь, группа). Может принимать одно из четырех значений:
PRINCIPAL - имя учетной записи пользователя или группы для которых назначаются права. Задаются в формате <ИМЯ_ЗАПИСИ> или <ДОМЕН\ИМЯ_ЗАПИСИ>.
ROLE_ID - идентификатор роли, содержащий необходимые права.
ENTITY_ID - идентификатор объекта, на который назначаются разрешения.
FLAG - переключатель хранит информацию о наследовании и типе учетной записи (пользователь, группа). Может принимать одно из четырех значений:
- 0 - учетная запись - пользователь, права не наследуются (no propagate);
- 1 - учетная запись - пользователь, права наследуются (propagate);
- 2 - учетная запись - группа, права не наследуются (no propagate);
- 3 - учетная запись - группа, права наследуются (propagate).

Системные роли существуют в vCenter изначально и не могут быть изменены или удалены. К системным относятся следующие роли:
Administrator - идентификатор роли (ROLE_ID): -1;
Read Only - идентификатор роли: -2;
No Access - идентификатор роли: -5.
Пользовательские роли могут быть созданы, отредактированы и удалены администратором vCenter. В vCenter после установки также присутствует несколько предустановленных (sample) пользовательских ролей:
Virtual machine power user (sample) - идентификатор роли (ROLE_ID): 4;
Virtual machine user (sample) - идентификатор роли: 5;
Resource pool administrator (sample) - идентификатор роли: 6;
VMware Consolidated Backup user (sample) - идентификатор роли: 7;
Datastore consumer (sample) - идентификатор роли: 8;
Network consumer (sample) - идентификатор роли: 9.
Все пользовательские роли хранятся в каталоге "DC=virtualcenter,DC=vmware,DC=int".
Для определения нужного ROLE_ID достаточно подключиться к каталогу (например, с помощью утилиты ADSIEdit) и в подразделении UserRoles найти требуемую группу.
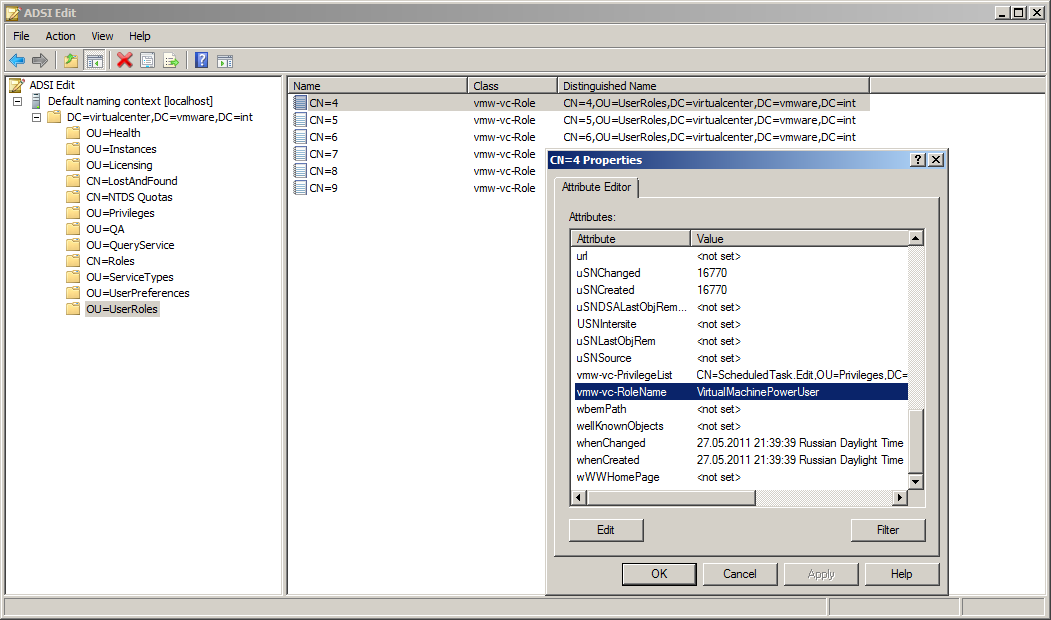
Наконец, значения ENTITY_ID для всех объектов виртуальной инфраструктуры хранятся в таблице dbo.VPX_ENTITY, поле ID.

Таким образом, если вы по ошибке удалили права для всех администраторов в vCenter, то можете сравнительно легко восстановить полный доступ, добавив соответствующую запись в таблицу. Однако, верно и обратное - любой администратор SQL сервера, где размещается база vCenter, может получить полный доступ к вашей виртуальной инфраструктуре.

























